Dieser Artikel ist der dritte Teil einer Serie über die Sicherstellung der Performance von Unternehmensanwendungen in DevOps Szenarien. Im ersten Teil sind wir zunächst auf die grundlegenden Herausforderungen bei der Evaluation der Performance eingegangen, der sich Software-Hersteller, -Betreiber oder -Nutzer durch DevOps Konzepte wie Continuous Delivery stellen müssen. In dem zweiten Teil haben wir die Perspektive der Entwicklung (Dev) beleuchtet und vorgestellt, welche Ansätze existieren, um die vorgestellten Herausforderungen aus Dev-Sicht zu adressieren. In diesem dritten Teil nehmen wir die Perspektive des IT-Betriebs ein und beschreiben Herangehensweisen um die Herausforderungen aus Ops-Sicht zu lösen.
Jedes Monitoring ist eine historische Betrachtung
Ein wesentliches Instrument zur Sicherstellung der Performance sobald eine Anwendung im Betrieb ist, ist der Einsatz von Monitoringwerkzeugen der (laut Gartner [4]) aktuellen Marktführer AppDynamics, Dynatrace oder New Relic. Diese Werkzeuge bieten alle grundsätzlich die Fähigkeit, Messdaten über den aktuellen Stand von Anwendungen und Serversystemen zu erheben oder diese historisch zu analysieren. Meist bieten diese Werkzeuge nicht nur grobgranulare Metriken über die Ressourcenauslastung der Server oder einzelner Prozesse, sondern auch detaillierte Einblicke in die Performance-Metriken einzelner Nutzer-Transaktionen. Man kann also bis auf Methoden im Source-Code verfolgen, wo Probleme aufgetreten sind.
Ein großes Problem von allen Monitoringwerkzeugen ist jedoch, dass nur Daten über Transaktionen erhoben werden können, die schon stattgefunden haben!
Das bedeutet, sobald ein Monitoringwerkzeug anzeigt, dass es Probleme gibt, wurden Nutzer bereits beeinträchtigt. Es ist dabei unerheblich wie viele Details ein solches Werkzeug bietet – Wenn mehrere hundert oder tausend Nutzer eine schlechte Erfahrung mit Ihrer Software gemacht haben, ist die Wahrscheinlichkeit, dass diese als Kunden wiederkehren, oder als Mitarbeiter motiviert mit der Software arbeiten, eher gering.
Es ist daher nicht möglich mit solchen Werkzeugen proaktiv zu planen. Wenn Sie sich also fragen, welche Auswirkung eine Änderung der Deployment-Topologie oder des Workloads hat, können Sie dies erst sehen, wenn diese Änderungen bereits auf Produktion vollzogen wurde oder Sie die geplanten Änderungen auf einer Testumgebung vermessen haben. Wie bereits in den vorherigen Teilen dieser Serie erläutert, ist dies ein sehr kostspieliges Unterfangen. Wie geht man aber damit um? Und ist proaktive Planung im Zeitalter von Cloud-Infrastrukturen noch notwendig?

Proaktive Planung ist unabhängig vom Betriebsmodell wichtig (on-premise vs. cloud)
Oft wird in heutzutage argumentiert, dass durch die Flexibilität moderner Betriebsmodelle in eigenen Rechenzentren mit Virtualisierungslösungen oder auf Cloud-Infrastrukturen eine proaktive Planung nicht mehr notwendig ist, da man ja flexibel Ressourcen dazu- oder abschalten kann. Was dabei jedoch nicht berücksichtigt wird, ist, dass diese Annahme zunächst schön klingt, aktuell jedoch nicht für alle Arten von Anwendungen der Realität entspricht. Die wesentlichen Probleme, die eine solche flexible Adaption verhindern sind die folgenden:
- Performance-Probleme sind meist in der Software-Architektur verborgen und führen oft dazu, dass die verfügbare Hardware nicht voll ausgenutzt werden kann [9].
- Aktuelle Laufzeitumgebungen (JDKs etc.) sind nicht ohne Neustart in der Lage, auf neu dazu geschaltete Rechenkapazität zu reagieren [6].
- Es gibt derzeit keine etablierten Metriken und Messverfahren um die „Elastizität“ von virtualisierten Infrastrukturen zu bestimmen [5]. Dadurch herrscht eine große Unsicherheit, inwieweit eine bestimmte Infrastruktur zuverlässig und zeitnah Lastspitzen erkennt und auf diese reagieren kann.
- Man hat bei Cloud-Anbietern nur bei sehr kostspieligen Instanztypen [7] eine Zusicherung bestimmter Ressourcen, es ist daher sehr undeterministisch, wie sich einige Instanzen über ihre Laufzeit hinweg verhalten.
- Viele Lizenzmodelle traditioneller Softwaresysteme (z.B. Middleware- oder Datenbanksysteme) sind abhängig von der Anzahl der genutzten CPU Kerne [8] oder anderen Infrastrukturaspekten. Daher können diese Systeme nicht flexibel skaliert beziehungsweise die flexible Skalierung würde sehr hohe Kosten verursachen.
- Viele traditionelle Unternehmensanwendungen erwarten eine Synchronisierung der Daten auf irgendeiner Ebene der Architektur (meist der Datenbank) um immer mit dem aktuellsten Stand zu arbeiten – dies reduziert die Flexibilität im Vergleich zu den „Verticals“ moderner Webanwendungen bei denen die Synchronisierungsanforderungen geringer sind und asynchron im Hintergrund bearbeitet werden können [9].
Aus den genannten Gründen ist es auch in Zukunft unabdingbar, größere Änderungen an der IT-Infrastruktur proaktiv zu planen, um nicht in unvorhersehbare Probleme oder unnötige Kosten zu laufen. Wie geht man jedoch damit um, wenn man auch im Betrieb das Ziel der schnellen Release-Frequenz (siehe Teil 1 dieser Serie) unterstützen will?
Eine grundlegende Anforderung für eine proaktive Planung ist das Vorliegen ausreichender Daten. Dies können aktuelle Messdaten aus Produktion sein sowie Informationen über Änderungen aus der Entwicklung. Messdaten aus Produktion können Sie mit Hilfe des RETIT Capacity Managers (RCM) in Performance-Modelle transformieren um flexibel, schnell und kostengünstig Änderungen an der Hardwareinfrastruktur, des Workloads oder der Deployment-Topologie durch Simulationen zu evaluieren. Ein paar beispielhafte Fragestellungen sind in der folgenden Abbildung dargestellt. Sollten die Daten aus der aktuellen Produktionsumgebung für eine Anwendung nicht mehr repräsentativ sein (z.B. durch wesentliche neue Funktionen), können Sie die von der Entwicklung bereitgestellten Modelle (siehe Teil 2 dieser Serie) zu diesem Zweck nutzen. Auf diese Weise können Sie ohne nennenswerte Verzögerungen proaktiv evaluieren ob bestimmte Änderungen eine Anpassung Ihrer IT-Infrastruktur erfordert, und so das Ziel der schnellen Release-Frequenz optimal unterstützen.
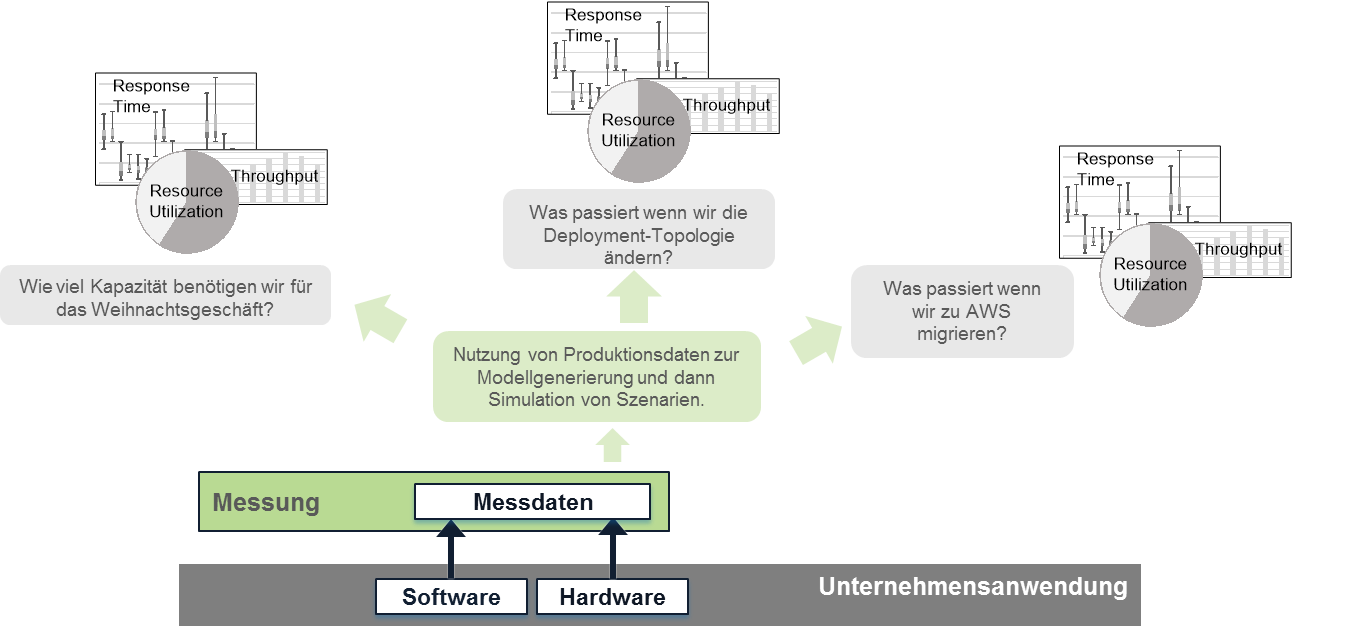
Die Kostentransparenz von Cloud-Lösungen führt zu Fragestellungen, die bisher nur Mainframe-Nutzer hatten
Moderne Betriebsmodelle in eigenen Rechenzentren mit Virtualisierungslösungen oder auf Cloud-Infrastrukturen ermöglichen es flexibel auf die Ergebnisse der proaktiven Planung zu reagieren und die IT-Infrastruktur den geänderten Anforderungen anzupassen. Betrachtet man jetzt speziell extern gehostete Cloud-Infrastrukturen ist zu beachten, dass jeder Zukauf von Instanzen sofort in der monatlichen Rechnung an den Einkauf sichtbar ist [3]. Diese unterscheiden sich deutlich von internen Betriebsmodellen, bei denen kleinere Änderungen, die keine Anschaffung zusätzlicher Hardware erfordern, meist nicht außerhalb der IT sichtbar sind.
Aus dem genannten Grund werden sich in der Zukunft immer mehr Unternehmen mit Fragestellungen beschäftigen, die bisher nur für Nutzer von Mainframesystemen relevant waren, da hier schon lange nach verbrauchter Rechenleistung abgerechnet wird [1,2]:
- Wer ruft welche Business-Transaktion auf und wie viele Ressourcen werden druch diesen Aufruf verbraucht?
- Wie viele Infrastrukturkosten entstehen durch eine Business-Transaktion?
- Wie können die Infrastrukturkosten einzelnen Business-Units oder Nutzergruppen zugeordnet werden?
Der Hintergrund dieser Fragen ist die Kostentransparenz, die es jetzt jederzeit erlaubt zu evaluieren, wie effizient die IT betrieben wird und wie sich die Kosten zwischen Lohn-, Infrastruktur- und Mietkosten aufteilen. Da sich jede Änderungen im Ressourcenverbrauch einzelner Unternehmensanwendungen und dem Verhalten der Nutzer sofort in den monatlichen Kosten niederschlägt, ist es wünschenswert, diese nach dem Verursacherprinzip umzulegen, also die Abteilungen innerhalb eines Unternehmens entsprechend Ihrer IT-Ressourcenbedarfe an den Kosten zu beteiligen. Dies versuchen Unternehmen mit Mainframes schon seit einigen Jahren [1,2], da die Kostenstransparenz einen großen Handlungsdruck auf die IT erzeugt.
Performance-Modelle können in solchen Szenarien helfen die hierzu notwendigen Berechnungen durchzuführen und die erforderlichen Datenquellen zu integrieren. In der folgenden Abbildung ist dies beispielhaft für ein Kundenszenario dargestellt. In diesem Szenario wurden die Kosten für die Einführung neuer Businessprozesse in eine service-orientierte Anwendungsarchitektur (SOA) für die beauftragende Business-Unit berechnet. Hierzu wurden APM-Daten aus der UI- und Serviceschicht mit Informationen über die Businessprozesse und Software-Designs integriert:
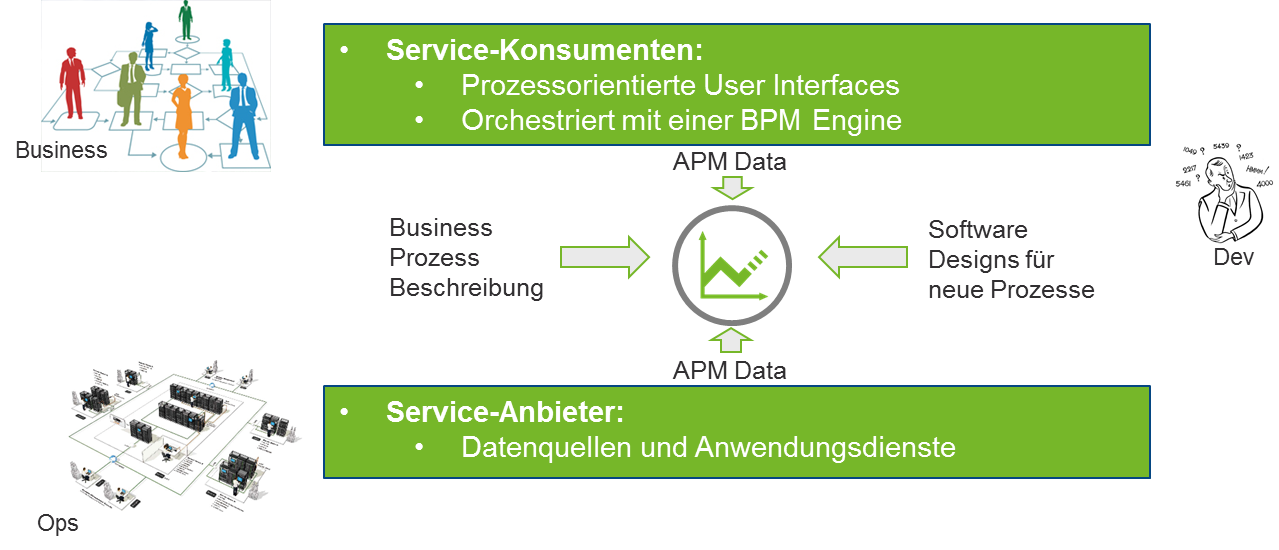 Mit Hilfe von Simulationen auf Basis dieser Daten konnten allen Beteiligten die für sie notwendigen Informationen zur Verfügung gestellt werden, um entsprechende Investitionsentscheidungen zu treffen und die Kosten auf die entsprechenden Business-Units und Service-Anbieter umzulegen. Ein paar beispielhafte Antworten, die auf Basis dieser Informationen gegeben werden konnten, sehen Sie hier:
Mit Hilfe von Simulationen auf Basis dieser Daten konnten allen Beteiligten die für sie notwendigen Informationen zur Verfügung gestellt werden, um entsprechende Investitionsentscheidungen zu treffen und die Kosten auf die entsprechenden Business-Units und Service-Anbieter umzulegen. Ein paar beispielhafte Antworten, die auf Basis dieser Informationen gegeben werden konnten, sehen Sie hier:
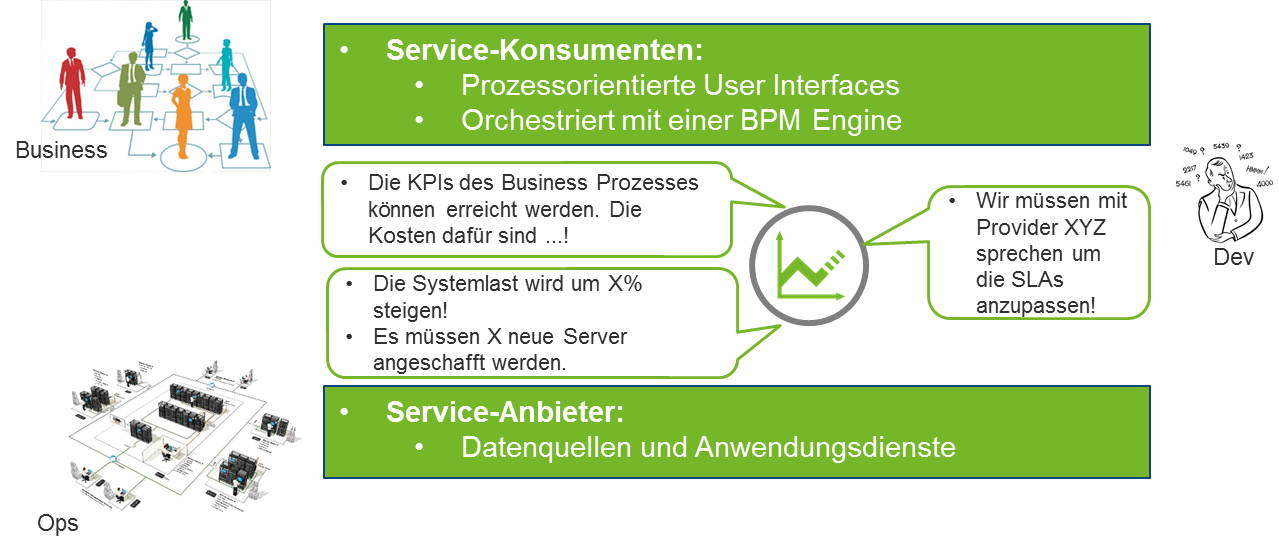
Durch den Einsatz von Performance-Modellen und den Fähigkeiten der Datenintegration können Sie daher vorsorgen und Antworten auf die für das Business relevanten Fragen geben. Sollten die RETIT-Lösungen Ihre Datenquellen nicht out-of-the-box unterstützen, passen wir diese gerne an Ihre Bedürfnisse durch unsere Beratungsleistungen an.
Performance-Feedback an Dev geben
Um die in Teil 2 dieser Serie angesprochene Eigenschaft der kontinuierlichen Iteration zwischen Entwicklung und Betrieb effizient auszunutzen, sollten Sie die Daten die durch APM Tools in Produktion erhoben werden, den Entwicklungsorganisationen zur Verfügung stellen! Nur so können Sie sicherstellen, dass alle aus den bisher erhobenen Daten lernen und sich die Performance und Ressourceneffizienz Ihrer Systeme kontinuierlich verbessert. Es ist jedoch darauf zu achten, welche Daten aus Produktion aus rechtlichen Gründen für die Entwickler sichtbar sein dürfen. Hier können Sie aber beim Export aus den Messwerkzeugen durch Filter für bestimmte Transaktionsdetails schnell Abhilfe schaffen.
Der kontinuierliche Austausch von Daten hilft nicht nur wie in Teil 2 dieser Serie aufgezeigt, frühzeitig Aussagen zur Performance neuer Releases zu treffen sondern auch, wie in der folgenden Abbildung dargestellt, die gesamte Kommunikation zu harmonisieren. Da man durch einen solchen Austausch nicht mehr nur in Krisensitationen („War-Room“ Sitzungen oder im Rahmen von „Task Forces“) zusammenarbeitet entsteht ein ganz neues Gemeinsamkeitsgefühl. Man geht also weg von Aussagen wie „Works in Dev – Ops Problem now!“ zu „Wir machen das gemeinsam!“.
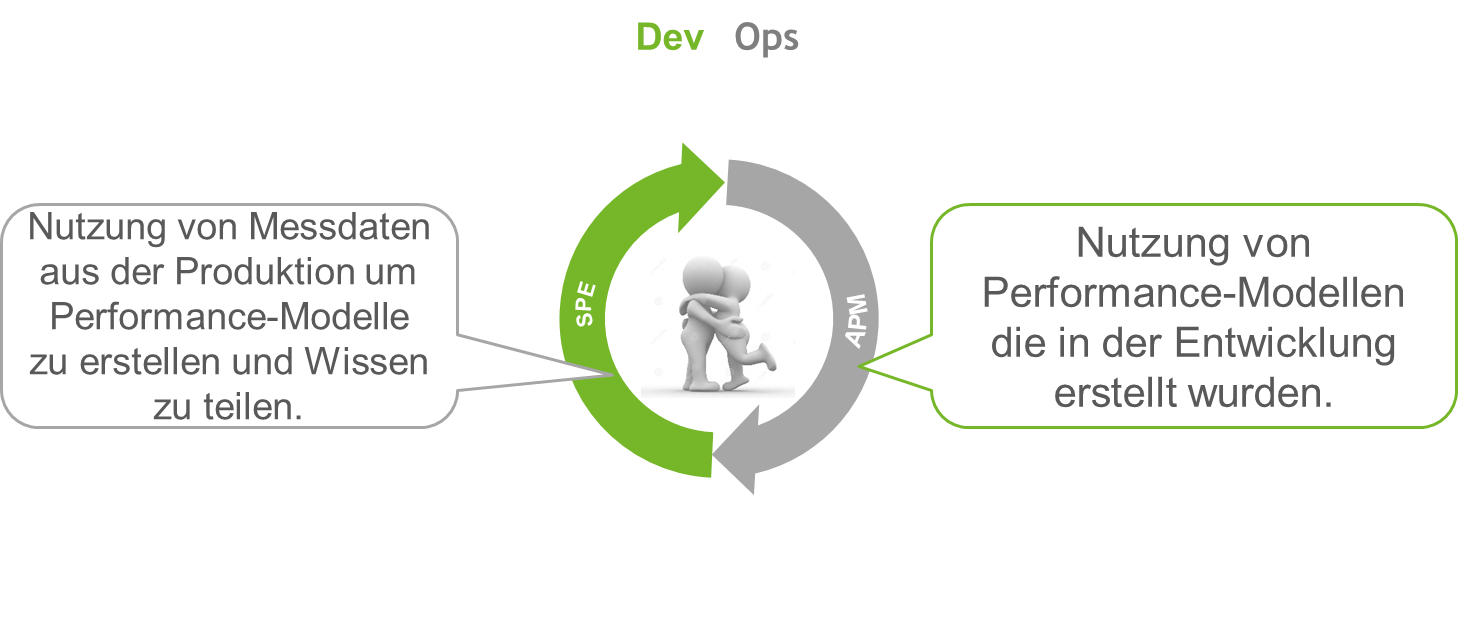
Performance-Modelle schließen aktuelle Lücken und ermöglichen kontinuierliches Software Performance Management in DevOps
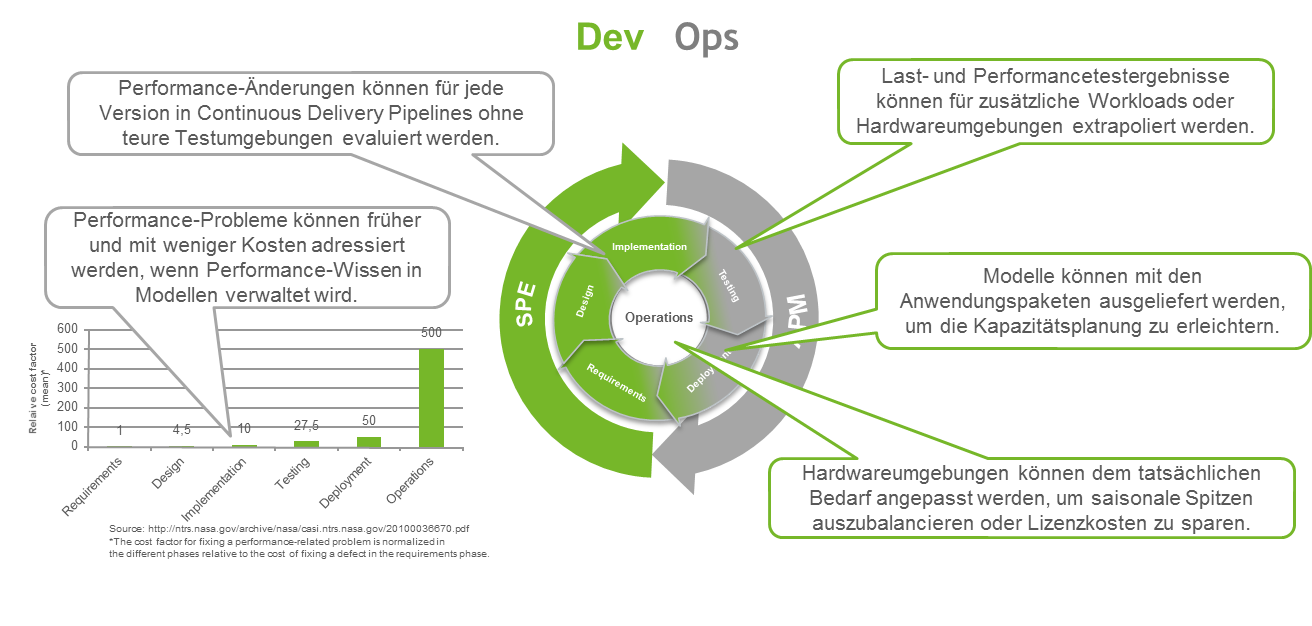
Wie Sie in Teil 1 dieser Artikelserie gesehen haben, erzeugen die schnellen Releasefrequenzen und die kontinuierliche Iteration zwischen Entwicklung und Betrieb ganze neue Herausforderungen, nicht nur aus funktionalen Gesichtspunkten, sondern auch aus Sicht der Performance. In Teil 2 und diesem Teil dieser Artikelserie haben wir Ihnen Lösungsmöglichkeiten für diese Herausforderungen aufgezeigt, die Performance-Modellierung voraussetzen um die konzeptionellen Nachteile der rein messbasierten Performance-Evaluationsansätze auszugleichen. In der folgenden Abbildung sehen Sie noch einmal die wesentlichen Vorteile der modellbasierten Performance-Evaluation entlang des gesamten Lebenszyklus eines Anwendungssystems, die Sie mit den RETIT Lösungen realisieren können.
Haben Sie Fragen, Feedback oder Kommentare zu diesem Artikel oder stehen Sie vor ähnlichen Herausforderungen? Schreiben uns an info@retit.de, wir helfen Ihnen gerne!
Möchten Sie das Thema Software Performance bei Ihnen im Haus wieder auf die Tagesordnung bringen? Wir diskutieren es mit Ihnen und halten einen Impulsvortrag zum Thema Performance bei Ihnen vor Ort. Sie übernehmen nur die Reisekosten – Schreiben uns an info@retit.de!
[1] http://www.performance-symposium.org/fileadmin/user_upload/palladio-conference/2014/slides/28_capgemini.pdf
[2] http://dss.in.tum.de/files/bichler-research/2007_brandl_cost_accounting.pdf
[3] http://www.computerwoche.de/a/cloud-computing-im-kosten-check,1235100
[4] http://apmblog.dynatrace.com/2015/12/28/reflecting-on-the-2015-gartner-magic-quadrant-for-application-performance-monitoring-apm/
[5] https://sdqweb.ipd.kit.edu/publications/pdfs/HeKoRe2013-ICAC-Elasticity.pdf
[6] http://dl.acm.org/citation.cfm?doid=1925861.1925869
[7] http://aws.amazon.com/ec2/purchasing-options/dedicated-instances/
[8] https://www-01.ibm.com/software/passportadvantage/pvu_licensing_for_customers.html
[9] https://www.retit.de/wp-content/uploads/2015/08/SPEC-RG-2015-001-DevOpsPerformanceResearchAgenda.pdf



